Spring Jpa환경에서 복합키 사용 시 Duplicate Exception이 발생하지 않는 이유
복합키란
복합키 정의를 살펴보면 다음과 같습니다
In database design, a composite key is a candidate key that consists of two or more attributes (table columns) that together uniquely identify an entity occurrence (table row). A compound key is a composite key for which each attribute that makes up the key is a foreign key in its own right. 출처 : wikipedia
둘 이상의 외래키 컬럼을 활용해 해당 엔티티의 기본키로 활용하는 걸 복합키라고 합니다. 기본키이기 때문에 당연히 중복되서 들어올 수 없습니다.
이런 속성 때문에 프로젝트를 진행하면서 두 값의 조합이 유일해야 하는 곳에 복합키를 사용해 봤습니다. ‘가게 테이블’과 ‘꽃 테이블’이 따로 존재할 때 특정 가게에 특정 꽃이 몇 개 남아있는가? 를 보여주는 테이블에 복합키를 사용했습니다

다음과 같은 설계로 특정 가게에 특정 꽃에 대한 수량 정보가 중복되는 일이 없도록 했습니다. 만약 'A가게'에는 '장미'라는 꽃이 5개 있다라는 정보가 (A가게, 장미) 라는 키로 데이터가 테이블에 들어가 있다면, 'A가게'의 '장미'를 키로 가지는 다른 데이터의 삽입을 방지하는 것이죠!
코드
코드로 살펴보면 다음과 같습니다.
Cargo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class Cargo {
@EmbeddedId
private CargoId id;
@MapsId("flowerId")
@ManyToOne
@JoinColumn(name="flower_id")
private Flower flower;
@MapsId("storeId")
@ManyToOne
@JoinColumn(name="store_id")
private Store store;
private Long stock;
}
위 코드를 써야되는게 맞지만, 테스트 편의를 위해 Store와 Flower객체를 연결하지 않고 단순화된 아래 코드를 사용하겠습니다
1
2
3
4
5
6
7
8
// 실제 객체와 매핑하지 않은 단순화된 Cargo 클래스
public class Cargo {
@EmbeddedId
private CargoId id;
private Long stock;
}
CargoId
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@Embeddable
public class CargoId implements Serializable {
private Long storeId;
private Long flowerId;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
CargoId cargoId = (CargoId) o;
return Objects.equals(storeId, cargoId.storeId) && Objects.equals(flowerId, cargoId.flowerId);
}
@Override
public int hashCode() {
return Objects.hash(storeId, flowerId);
}
}
테스트 코드
원하는대로 동작하는지 테스트 코드를 작성해 봅시다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
@Autowired
private CargoRepository cargoRepository;
@Autowired
private EntityManager em;
@Test
void test() {
Long storeId = 1L;
Long flowerId = 1L;
CargoId id = new CargoId(storeId, flowerId);
Cargo cargo1 = new Cargo(id, 100L);
cargoRepository.save(cargo1);
em.flush();
em.clear();
// 동일한 id로 객체 생성을 시도했기 때문에 Duplicate Exception이 발생하길 기대한다
Cargo cargo2 = new Cargo(id, 999L);
cargoRepository.save(cargo1);
em.flush();
em.clear();
}
예상과 다르게 테스트가 실패하지 않았습니다. 쿼리를 살펴보면 다음과 같습니다.
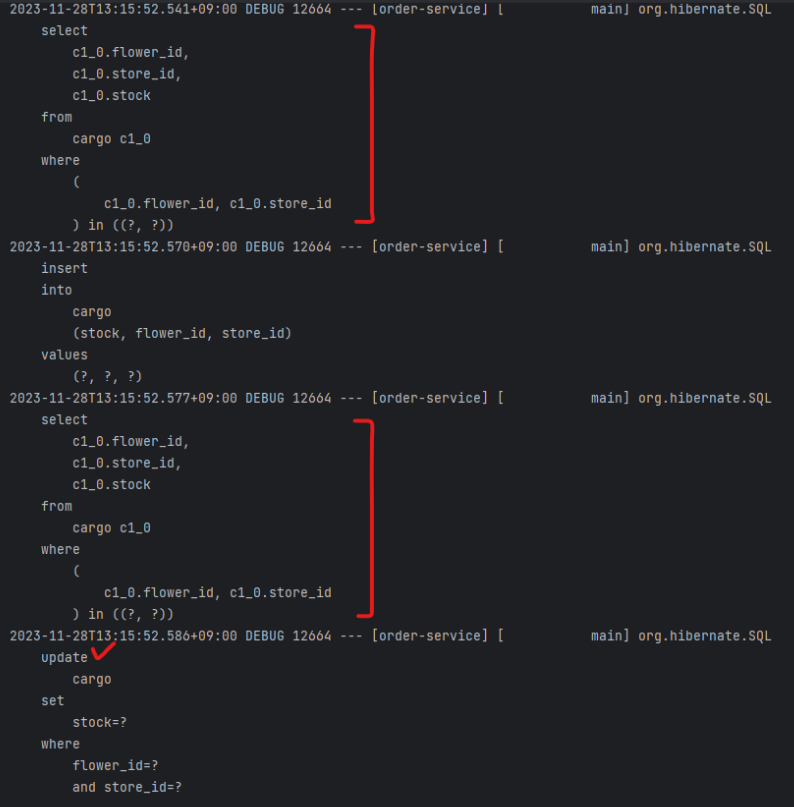
쿼리를 보면 특이한 점이 두 가지 발견됩니다.
- 첫째. 매 쿼리마다 조회 쿼리(select)가 나갑니다.
- 둘째. 두 번째 save에서 update쿼리가 나갔습니다.
이 문제는 복합키라서 발생하는 문제이기 이전에 Id 존재 여부에 의해 발생하는 문제입니다.
객체를 생성할 때 Id를 auto_increment로 설정하는 방법이 익숙할 것입니다. auto_increment를 활용하기 위한 코드는 다음과 같습니다.
1
2
3
4
5
6
7
8
public class Store {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String storeName;
}
JPA는 쿼리를 생성했을 때 곧바로 DB에 반영하지 않고 영속성 컨텍스트에 모아둡니다.
영속성 컨텍스트에서 엔티티를 구분하기 위해서는 Id가 반드시 필요합니다.
하지만 위와 같이 DB의 auto_increment를 활용하는 전략은 단순히 영속성 컨텍스트에 엔티티를 생성하는 것만으로는 Id를 알 수 없습니다.
그래서 JPA는 auto_increment를 활용하는 방식으로 객체를 생성할 때는 예외적으로 곧바로 flush를 통해 DB에 값을 넣고, DB에 의해 얻어온 Id값을 영속성 컨텍스트에 있는 객체에 넣어줍니다.
@GeneratedValue(strategy = GenerationType.IDENTITY) 전략을 사용하지 않고 한쪽의 key를 공유하는 @OneToOne의 경우도 이러한 문제가 발생할 가능성이 높습니다.
SimpleJpaRepository의 save코드를 살펴보면 다음과 같습니다. 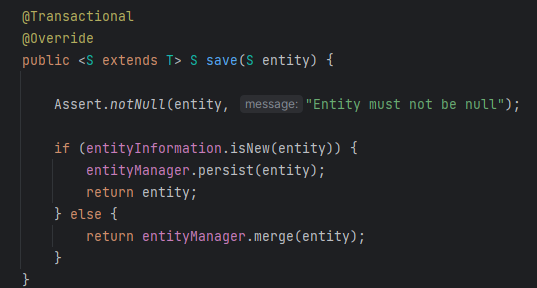
save는 @Id의 값이 이미 존재하면 persist가 아닌 merge를 실행합니다. 우리가 auto_increment전략을 쓰지 않고 직접 Id를 정의한 경우에는 @Id값이 이미 존재하기 때문에 새로운 객체가 아니라 판단해 persist가 아닌 merge를 실행합니다. merge는 update를 실행하기 위해 DB로부터 해당 Id값의 데이터를 찾아오기 위해 select쿼리를 실행합니다.
해결 방법
1. 서비스 로직에서 검사
JPA는 우리가 직접 설계한 코드가 아니기 때문에 이를 바꿀 수는 없습니다.
대신 우리가 서비스 로직에서 직접 해당 값이 존재하는지 확인해 Duplicate Exception을 발생시킬 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
@Test
void throwExceptionManually() {
Long flowerId = 1L;
Long storeId = 1L;
CargoId id = CargoId.builder()
.flowerId(flowerId)
.storeId(storeId)
.build();
Optional<Cargo> find = cargoRepository.findById(id);
if(find.isPresent()) {
throw new DuplicateKeyException("이미 존재하는 값입니다");
}else {
Cargo cargo = Cargo.builder()
.id(id)
.stock(199L)
.build();
cargoRepository.save(cargo);
}
}
- 정상적인 save는 여전히 select쿼리가 발생하기 때문에 좋은 방법은 아닌것 같습니다.
2. NativeQuery
위 문제는 결국 JPA를 사용하기 때문에 발생한 문제입니다. JPA를 사용하지 않는 NativeQuery를 이용하면 원하는대로 Duplicate Key 예외가 발생합니다.
다음과 같은 쿼리로 save를 진행하면 아래와 같은 에러가 발생합니다.
1
2
3
4
@Query(value = "insert into cargo(store_id,flower_id,stock) values(:storeId, :flowerId, :stock)",nativeQuery = true)
@Modifying
@Transactional
void saveWithNativeQuery(@Param("storeId") Long storeId, @Param("flowerId") Long flowerId, @Param("stock") Long stock);

3. Persistable
Persistable 인터페이스를 통해 새로운 엔티티인지를 판별하는 부분을 직접 설정할 수 있습니다.
다시 SimpleJpaRepository의 save를 살펴봅시다. save메서드는 entityInformation.isNew()로 persist를 할지 merge를 할지 경정합니다.
이때 SimpleJpaRepository의 entityInformation을 살펴보면 JpaEntityInformation타입을 주입받고 있습니다. 그리고 구체적으로 어떤 객체를 주입할지는 JpaEntityInformationSupport에 의해 정해지게 됩니다. 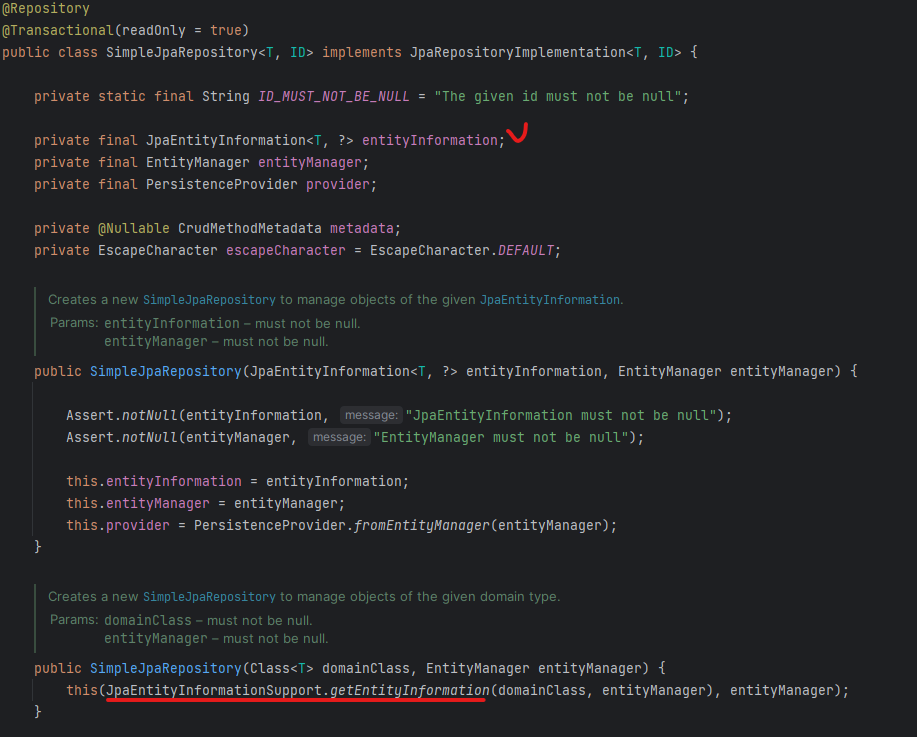
JpaEntityInformationSupport의 getEntityInformation은 Persistable.class.isAssignableFrom(domainClass)에 의해 구체적인 객체를 결정합니다.
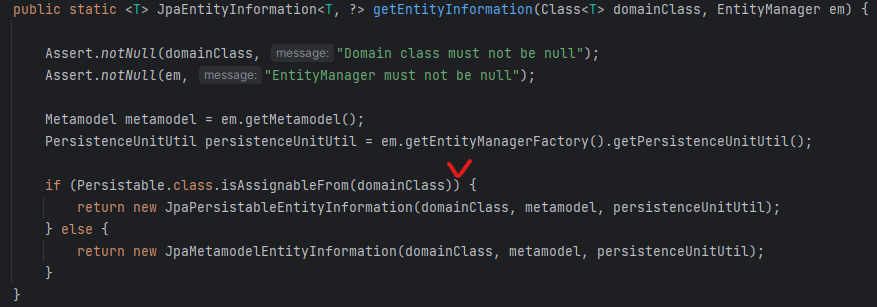
Persistable.class.isAssignableFrom(domainClass)는 domainClass가 Persistable을 상속하거나 구현했는지 여부를 판단합니다.
만약 Persistable을 상속했다면 그때는 JpaPersistableEntityInformation객체를 이용합니다. 해당 객체의 isNew()는 entity안에 있는 isNew() 메서드로 새로운 객체 여부를 판단합니다.
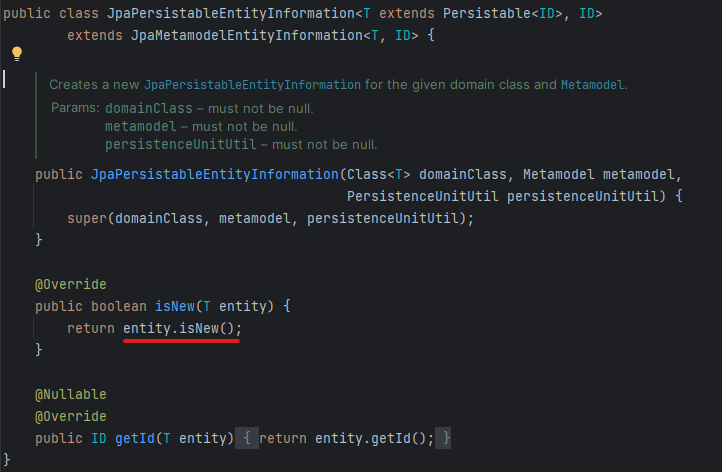
그러므로 우리의 Entity에 Persistable을 implements한 뒤 isNew()를 정의해 두면 해당 조건을 기준으로 객체의 persist 혹은 merge를 선택할 수 있게 됩니다!
Spring Data의 jpa docs에는 Persistable을 통해 새 엔티티를 판별하는 간단한 예제 코드를 제공해주고 있습니다.
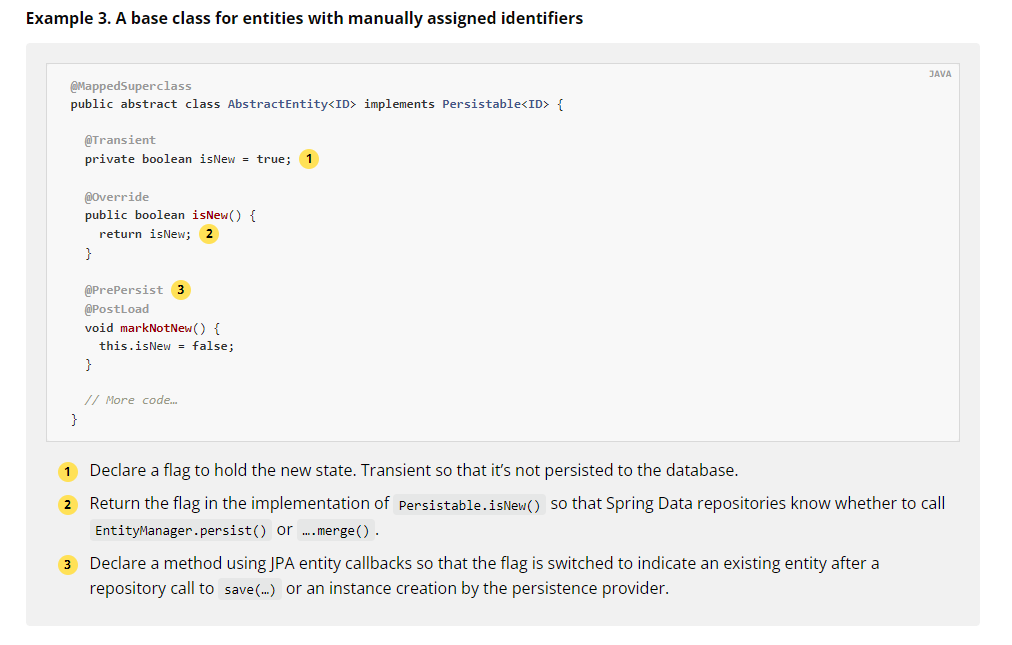
예제에 맞게 객체를 재정의해 보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public class Cargo implements Persistable<CargoId> {
@EmbeddedId
private CargoId id;
private Long stock;
@Transient
private boolean isNew = true;
@Override
public boolean isNew() {
return isNew;
}
@Override
public CargoId getId() {
return this.id;
}
@PrePersist
@PostLoad
void markNotNew() {
this.isNew = false;
}
}
동일한 Id를 사용하는 두 객체 모두 isNew속성을 true로 설정하고 save를 시도합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@Test
void test() {
Long storeId = 1L;
Long flowerId = 1L;
CargoId id = new CargoId(storeId, flowerId);
Cargo cargo1 = new Cargo(id, 100L, true);
cargoRepository.save(cargo1);
em.flush();
em.clear();
// 동일한 id로 객체 생성을 시도했기 때문에 Duplicate Exception이 발생하길 기대한다
Cargo cargo2 = new Cargo(id, 999L, true);
cargoRepository.save(cargo2);
em.flush();
em.clear();
}
키가 중복됐다는 에러를 받게 됩니다!

References
- https://taesan94.tistory.com/266
- https://velog.io/@yglee8048/JPA-Persistable
- https://kapentaz.github.io/jpa/Spring-Data-JPA%EC%97%90%EC%84%9C-insert-%EC%A0%84%EC%97%90-select-%ED%95%98%EB%8A%94-%EC%9D%B4%EC%9C%A0/#
- https://ttl-blog.tistory.com/852
- https://docs.spring.io/spring-data/jpa/docs/current-SNAPSHOT/reference/html/#jpa.entity-persistence.saving-entites